
Sauf indication contraire, toutes les performances boursières ci-dessous sont exprimées en € dividendes réinvestis
Le 20 janvier 2025, le département R&D d’un fonds d’investissement spéculatif chinois1 publiait son nouveau modèle d’intelligence artificielle générative, nommé « DeepSeek R1 ». Moins d’une semaine plus tard, l’indice SOX regroupant les plus grandes sociétés de semi-conducteurs au monde2 avait déjà perdu plus de 9% de sa valeur. Ce nouveau modèle, peu cher à concevoir et à faire fonctionner, vient questionner les besoins d’augmentation des capacités de calcul et de datacenters, alors même que des Etats comme les Etats-Unis ou la France viennent d’annoncer de grands plans d’investissements de plusieurs centaines de milliards d’euros. Sommes-nous en train d’assister à un bouleversement technologique ? Les grands gagnants d’hier comme Nvidia et OpenAI sont-ils voués à décliner ? Nous verrons que tout n’est pas aussi simple.
Qu’est-ce que « DeepSeek R1 » ?
C’est un modèle d’IA (intelligence artificielle) générative accessible à tous et qui se fonde sur deux approches algorithmiques innovantes. La première est la « mixture of expert », où le modèle est en fait une combinaison de plusieurs petits modèles chacun spécialisé dans leur domaine3, et où seule une petite partie de ces modèles sera mobilisée en cas de besoin (au lieu du modèle dans son ensemble). La deuxième approche est le « reinforced learning » par distillation : on prend un modèle existant et on améliore son entraînement, notamment en utilisant d’autres modèles d’IA existants pour gagner du temps et réduire les coûts.
A en croire le papier de recherche publié par DeepSeek le 20 janvier 2025, DeepSeek R1 atteint des niveaux de performances similaires ou légèrement supérieurs à ceux des meilleurs modèles américains comme ChatGPT 4o et ChatGPT o1, deux des derniers modèles d’OpenAI. Grâce aux nouvelles méthodes d’entraînement vues plus haut, le modèle serait également nettement moins coûteux à entrainer4 que des modèles comparables comme LlaMA 305B de Meta. En bref, DeepSeek R1 obtiendrait des niveaux de performances quasi identiques à ces grands modèles pour moins de 10% de leur coût d’entraînement, et pour une fraction de leurs coûts à l’utilisation.
Performance du modèle DeepSeek : très bonne, requêtes peu chères
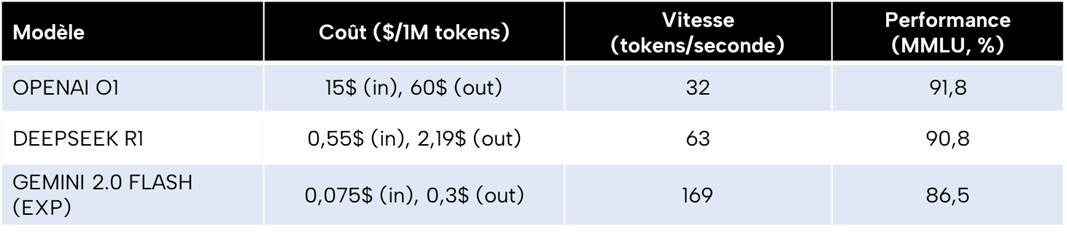
Source : ExponentialView, tiré des chiffres fournis par les entreprises concernées
Le modèle de DeepSeek marque-t-il un nouveau saut technologique ?
A première vue, la forte baisse du coût d’entraînement et du coût d’utilisation devrait permettre de limiter les besoins en capacités de calcul supplémentaire : des entreprises comme Alphabet/Microsoft/Amazon, qui vendent des services de cloud, pourraient ainsi proposer un modèle aussi performant que ChatGPT o1, tout en n’ayant besoin que de 10% des capacités de calcul qui lui étaient nécessaires auparavant. C’est ce raisonnement qui a inquiété les investisseurs et qui a fait baisser les sociétés de semi-conducteurs en bourse : pourquoi continuer d’acheter 100 puces à Nvidia ou Broadcom alors que 10 suffiraient désormais ?
La vérité semble être plus complexe : malgré l’annonce de DeepSeek, les principaux acteurs de l’IA/Cloud aux Etats-Unis (Amazon, Microsoft, Alphabet et Meta) ont annoncé vouloir investir des montants record dans leurs infrastructures de calcul. En 2025, les CAPEX de ces entreprises devraient atteindre 320 Mds de dollars, soit une hausse de près de 40% par rapport à 2024, qui était déjà une année de forte croissance5 !
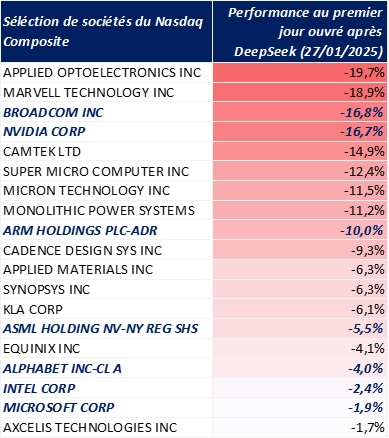
Source : Bloomberg, analyse DTG
Mais alors pourquoi tant d’investissements alors que le progrès algorithmique permet de faire des économies substantielles en termes de coût de calcul ? En fait, le progrès algorithmique a toujours existé et DeepSeek est loin d’être le seul acteur à faire un bond d’efficacité. En 2024 par exemple, le modèle Claude 3.5 Sonnet de la société Anthropic avait présenté d’aussi bonnes performances que GTP-4 (sorti 15 mois plus tôt), mais pour seulement 10% du coût d’entraînement. De plus, malgré le progrès algorithmique les coûts d’entraînement continuent d’augmenter de 2,4 fois par an depuis 2016 : le progrès, qu’il soit algorithmique ou physique (i.e. meilleures puces), est vital si l’on veut que l’IA soit abordable et se diffuse dans nos économies. Enfin, les GAFAM6 se sont toujours servis de la baisse des coûts pour augmenter l’entraînement de leurs modèles : avec le progrès algorithmique, les modèles sont maintenant plus performants à coût égal et créent davantage de valeur pour ces sociétés, car ils sont utilisables dans des domaines plus larges. En bref, cette innovation s’inscrit dans la continuité du progrès observée dans le monde de l’IA générative et ne remet pas en cause les investissements, toutes choses égales par ailleurs.
La vraie rupture ? L’innovation vient de la Chine
Si l’innovation et les performances qu’apportent le modèle « DeepSeek R1 » s’inscrivent dans la continuité du progrès algorithmique, c’est le lieu qui dénote. DeepSeek, une société chinoise, a réussi l’exploit de créer un modèle d’IA aussi performant que ses homologues américains pour une fraction du coût d’entraînement, alors même que la Chine est sujette aux limitations à l’importation de technologies de semi-conducteurs occidentales. En bref, « DeepSeek R1 » a pu se construire en n’utilisant que des puces Nvidia bridées et autorisées à l’export vers la Chine (les puces « H800 »). La société DeepSeek n’est pas le seul acteur chinois à innover malgré les contraintes : les fabricants de puces chinois comme SMIC semblent parvenir à produire des puces avancées7 « Kirin », conçues par Huawei, sans utiliser les machines les plus modernes d’ASML8, interdites à l’exportation vers la Chine.
Dans ce contexte, l’administration Trump a déjà annoncé que des restrictions supplémentaires à l’exportation de technologies de semi-conducteur étaient à l’étude avec les partenaires européens et japonais. En plus des guerres commerciales que connaissent actuellement nos économies, une accentuation de la guerre technologique entre les occidentaux et la Chine ne serait pas sans conséquence : avec 17 Mds de dollars de ventes réalisées en Chine, Nvidia y est exposé à hauteur de plus de 10% de son chiffre d’affaires. Le constat est similaire pour des sociétés comme ASML, dont le chiffre d’affaires 2024 réalisé en Chine a atteint des records (près de 50% des ventes).
A ce jour, les sociétés de semi-conducteurs semblent sujettes à de mauvaises nouvelles de court terme. Pour autant, cela ne signifie pas nécessairement que leur potentiel de croissance à long-terme est obéré, compte tenu des perspectives de croissance de l’Intelligence Artificielle.
Achevé de rédiger le 17/04/2025 par Quentin Lelong, gérant-analyste.
Ce document est exclusivement conçu à des fins d’information. Les données chiffrées, commentaires ou analyses figurant dans ce document reflètent le sentiment à ce jour de Dubly Transatlantique Gestion sur les marchés, leur évolution, leur réglementation et leur fiscalité, compte tenu de son expertise, des analyses économiques et des informations publiques possédées à ce jour. Ces données sont en conséquence susceptibles de changer à tout moment et sans avis préalable. Les éventuelles informations faisant référence à des instruments financiers contenues dans ce document ne constituent en aucune façon une analyse financière, un conseil en investissement ni une recommandation d’investissement. Leur consultation est effectuée sous votre entière responsabilité. Toute opération de marché sur un instrument financier comporte des risques, en particulier un risque de perte en capital. Toute reproduction de ce document est formellement interdite sauf autorisation expresse de Dubly Transatlantique Gestion.